Hadoop基本概念
Table of Contents
Hadoop是什么
Hadoop是一个分布式计算的解决方案, 可编写和运行分布式应用, 以处理大规模数据, 是专为离线和大规模数据分析而设计的, 并不适合那种对几个记录随机读写的在线事务处理模式.
在Hadoop中, 不管数据是什么类型的, 最终都会转化为k-v对, k-v对是基本数据单元. 对于非结构化数据, 使用MapReduce来代替SQL, 而对于关系型数据库, 可使用Hive.
分布式计算的核心在于利用分布式算法把运行在单台机器上的程序扩展到多台机器上并行运行, 从而使得数据处理能力成倍增加, 但是这种分布式计算一般对编程人员要求很高, 而且对服务器也有要求, 导致成本非常高. Hadoop就是为了解决这个问题诞生的. Hadoop可以很轻易地把多个廉价的机器组成分布式节点, 然后编程人员也不需要知道分布式算法, 只需要根据MapReduce的规则定义好接口, 剩下的就交给Hadoop.
Hadoop的版本演进
Hadoop 1.0
Hadoop1.0 = HDFS + MapReduce
HDFS = NameNode + n * DataNode
MapReduce = JobTracker + n * TaskTracker
Hadoop 2.0
Hadoop 2.0 = HDFS + YARN + MapReduce
HDFS = NameNode + n * DataNode + Secondary NameNode
YARN = ResourceManager + NodeManager
针对Hadoop1.0中NameNode HA不支持自动切换且切换时间过长的风险,Hadoop2.0提出了基于共享存储的HA方式,支持失败自动切换切回。
针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation机制,它允许多个NameNode各自分管不同的命名空间进而实现数据访问隔离和集群横向扩展。
针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN,它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现。其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。相比于 Hadoop 1.0,Hadoop 2.0框架具有更好的扩展性、可用性、可靠性、向后兼容性和更高的资源利用率以及能支持除了MapReduce计算框架外的更多的计算框架,Hadoop 2.0目前是业界主流使用的Hadoop版本。
Map与Reduce
以词频统计为例.
Map阶段. 多台机器同时读取文件的各个部分, 各自统计, 产生类似: (hello, 11000), (world, 15111)等pair.
Reduce阶段. 多台机器启动Reduce处理, 如机器A收到所有以A开头的统计结果, 机器B收到所有以B开头的统计结果, 然后这些Reduce将再次汇总, 如: (hello, 11000) + (hello, 11111) + (hello, 10000) = (hello, 32111).
虽然这是个很简单的模型, 但很多算法都可以用这个模型来描述. MapReduce简单粗暴, 过于笨重, 于是出现了第二代计算引擎Tez和Spark, 让Map和Reduce之间的界限更模糊, 数据交换更灵活, 减少磁盘读写, 以便更方便地描述复杂算法, 取得更高的吞吐量. 但事情仍然繁琐, 于是出现了Pig和Hive. Pig以接近脚本的方式去描述MapReduce, Hive则用SQL. 它们把脚本和SQL语言翻译成MapReduce程序, 丢给计算引擎去计算.
数据仓库架构: 底层HDFS, 上一层跑MapReduce/Tez/Spark, 再上面跑Hive/Pig. 或者直接在HDFS上跑Impala, Drill, Presto.
如果速度还要更快, 则是Storm. 流计算的思路就是, 数据在流进来的时候就处理掉它. 它的优点是速度快, 缺点是不灵活, 因为想要统计的东西必须预先知道, 否则数据流过了就没了.
键值数据库
键值数据库可以快速地获取与某个Key绑定的数据. 如用身份证号, 查到与这人相关的数据. 虽然这个动作用MapReduce也能完成, 但是可能需要扫描整个数据集.
键值数据库的一个应用是, 根据订单号查找订单内容的页面, 整个网站的订单数据无法单机数据库存储.
键值数据库基本无法处理复杂的计算, 大多没法JOIN和聚合, 没有强一致保证(不同数据分布在不同机器上, 每次读取也许会读到不同的结果, 无法处理类似银行转账那样的强一致性要求的操作).
Hadoop的组成
HDFS
特征
- 将大量数据存储到大量的节点中, 支持单个大文件.
- 高可靠(多个备份).
- 易扩展(简单加入更多服务器).
- 数据尽可能根据其本地局部性进行访问与计算.
缺陷
- 为实现高吞吐量导致延迟高.
- 不适合小文件存取, 会占用NameNode大量内存, 寻道时间超过读取时间.
- 一次只能有一个写者, 仅支持append.
NameNode
- 管理文件系统的命名空间
- 维护文件系统树
- 存储元数据
元数据通过以下文件和过程持久化到磁盘中:
- fsimage: 对元数据定期备份
- edits: 存放一定时间内的HDFS操作记录
- checkpoint: 检查点
运行NameNode会消耗大量的内存和IO资源, 因此, 为了减轻机器的负载, 驻留NameNode的服务器通常不会存储用户数据或者执行MapReduce程序的计算任务, 这意味着NameNode服务器不会同时是DataNode或者TaskTracker.
DataNode
DataNode将HDFS数据块读取或者写入到本地文件系统的实际文件中.
如果要对HDFS文件进行读写, 文件会被分割成多个块, 由NameNode告知客户端, 每个数据块驻留在哪个DataNode, 客户端直接与DataNode通信, 来处理与数据块相对应的本地文件.
DataNode会与其他DataNode通信, 复制这些数据块以实现冗余.
Secondary NameNode
Secondary NameNode是一个监测HDFS集群状态的辅助守护进程, 通常独占一台服务器. 它与NameNode通信, 根据集群所配置的时间间隔获取HDFS元数据的快照.
由于NameNode是Hadoop集群的单一故障点, Secondary NameNode的快照可以有助于减少停机的时间并降低数据丢失的风险.
JobTracker
JobTracker是应用程序和Hadoop之间的纽带. 一旦提交代码到集群上, JobTracker就会确定执行计划, 包括决定处理哪些文件, 为不同的任务分配节点, 监控所有任务的运行. 如果任务失败, JobTracker将自动重启任务.
一个Hadoop集群只有一个JobTracker, 通常运行在服务器集群的主节点上.
TaskTracker
TaskTracker管理各个任务在每个从节点上的执行情况. 它负责与JobTracker通讯, 如果JobTracker在指定的时间内没有收到来自TaskTracker的心跳包, 就会假定TaskTracker崩溃了, 进而重新提交相应的任务到集群的其他节点中.
HDFS的工作原理
分离元数据和数据
在传统的文件系统中, 因为文件系统不会跨越多台机器, 元数据和数据存储在同一台机器上.
HDFS里, 元数据存储在NameNode上, 数据存储在DataNode的集群上.
HDFS写过程
场景: Client要将zhou.log文件写入到HDFS. 过程如下图所示:
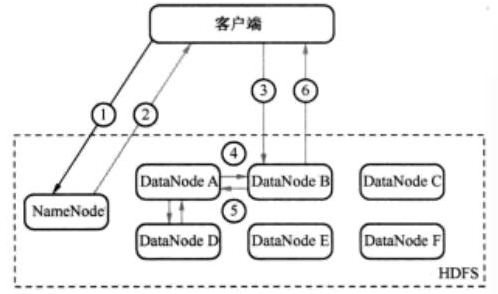
- Client->NameNode, 告知其要将zhou.log文件写入.
- NameNode->Client, 告知其要写入到DataNodeA, DataNodeB, DataNodeD, 并直接与DataNodeB联系.
- Client->DataNodeB, 让DataNodeB保存一份zhou.log文件, 并让其将副本发送给DataNodeA和DataNodeD.
- DataNodeB->DataNodeA, 让DataNodeA保存一份zhou.log文件, 并让其发送一份副本给DataNodeD.
- DataNodeA->DataNodeD, 让DataNodeD保存一份zhou.log文件.
- DataNodeD->DataNodeA.
- DataNodeA->DataNodeB.
- DataNodeB->Client, 表示写入完成.
确保数据一致性: HDFS认为, 直到所有要保存数据的DataNodes确认它们都有文件的副本时, 数据才被认为是写入完成.
HDFS读过程
HDFS读过程如图所示:
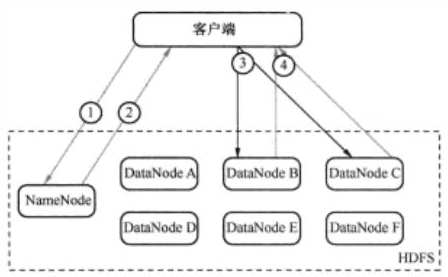
- Client->NameNode, 询问应该从哪里读取文件.
- NameNode->Client, 告诉Client相应的数据块的信息(DataNode的IP地址, 数据块ID).
- Client->DataNode, 请求数据块.
- DataNode->Client, 返回文件内容, 关闭连接.
Client并行从不同的DataNode中获取文件其中的一个数据块, 然后将这些数据块整合起来, 拼成完整的文件.
通过副本快速恢复硬件故障
DataNode周期性(一般为3s)地发送心跳包给NameNode. 如果NameNode在预定的时间内(一般为10min)没有收到心跳信息, 则认为DataNode出现故障. 于是, DataNode被移除, 并启动一个进程来恢复数据.
Generated by Emacs 25.x(Org mode 8.x)
Copyright © 2014 - Pinvon - Powered by EGO
