支持向量机
Table of Contents
什么是支持向量机?
假设要将一组数据集分成两类.
如果数据集是二维的, 能否找出一条直线将两组数据分开?
如果数据集是三维的, 能否找出一个平面将两组数据分开?
如果数据集是N维的, 能否找出一个超平面, 将两组数据分开?
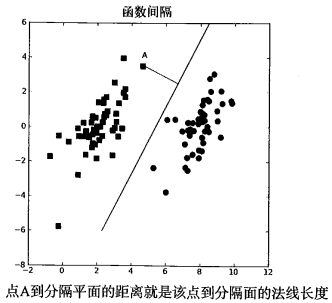
如果能找到这样一个超平面, 我们就将其称为 分隔超平面. 我们希望能找到离分隔超平面最近的点, 使它们离分隔超平面尽可能的远. 如果将点到分隔面的距离称为 间隔, 我们希望的就是间隔尽可能的大.(原因是如果我们犯了错, 或者在有限数据上训练分类器的话, 我们希望分类器能够尽可能地健壮一些).
支持向量 就是离分隔超平面最近的那些 点. 我们要做的, 就是 最大化支持向量到分隔面的距离.
支持向量机的优缺点: 优点: 泛化错误率低, 计算开销小, 结果易解释. 缺点: 对参数调节和核函数的选择敏感, 原始分类器不加修改仅适用于处理二类问题.
寻找最大间隔
分隔超平面在数学上, 可以写成: \(\pmb w^{T}\pmb x + b\). 其中, \(x\) 相当于一系列的特征, \(w\) 是其系数.
点 \(A\) 到分隔超平面的法线长度为: \(\frac{|\pmb w^{T}\pmb x + b|}{||\pmb w||}\). 如图所示:
分类器求解的优化问题
既然是分类器, 就需要在得到一系列特征之后, 对数据进行分类.
支持向量机中, 我们使用的函数与Sigmoid函数类似. 不同之处在于, 如果输入小于0, 则输出-1, 反之则输出+1.
我们需要将一系列的特征和系数( \(\pmb w^{T}\pmb x + b\) )作为输入传递给该函数, 根据输出来分类.
使用+1或-1, 而不使用0或1, 是为了方便数学上的处理.
间隔使用 \(label * (\pmb w^{T}\pmb x + b)\) 来表示. 其中, \(label\) 为+1或-1.
如果数据点处于正方向(即+1类)并且离分隔超平面很远时, \(\pmb w^{T}\pmb x + b\) 是一个很大的正数, 乘以 \(label\) 后仍然是个很大的正数.
如果数据点处于负方向(即-1类)并且离分隔超平面很远时, \(\pmb w^{T}\pmb x + b\) 是一个很大的负数, 乘以 \(label\) 后是个很大的正数.
不管怎样, 都是很大的正数, 方便处理.
特征需要自己去提取, 所以现在的目标是要找出系数 \(\pmb w\) 和 \(b\) . 为了找出它们, 还要先找到具有最小间隔的数据点, 即要先找到支持向量.
最大化的间隔可以写成:
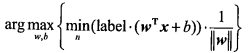
直接求解该问题非常困难. 如果假设 \(label \cdot (\pmb w^{T}\pmb x + b) \geq 1.0\), 且假设数据必须100%线性可分. 使用拉格朗日乘子法, 可以将优化目标函数转化成如下形式:
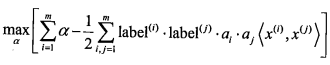
约束条件为: \(C \geq \alpha \geq 0\), 且 \(\sum_{i=1}^{m} \alpha_i \cdot label^{(i)} = 0\). 其中, C用于控制"最大化间隔"和"保证大部分点的函数间隔小于1.0".
所以, 问题最终转化成求解所有的 \(\alpha\).
Platt的SMO算法
Platt在1996年发布SMO算法, 用于训练SVM. SMO算法是将大的优化问题分解为多个小优化问题来求解的. 在结果完全相同的同时, SMO算法的求解时间短很多.
工作原理: 每次循环中, 选择两个 \(\alpha\) 进行优化处理. 一旦找到一对合适的 \(\alpha\), 就增大一个同时减小另一个. 所谓"合适", 是指这两个 \(\alpha\) 要在间隔边界之外, 并且还没进行过区间化处理或不在边界上.
简化版SMO
简化版SMO的伪代码:
创建一个alpha向量并将其初始化为0向量
当迭代次数 < 最大迭代次数时
对数据集中的每个数据向量
如果该数据向量可以被优化
随机选择另一个数据向量
同时优化这两个向量
如果两个向量都不能被优化, 退出内循环
如果所有向量都没被优化, 增加循环次数, 继续下一次循环
完整Platt SMO算法
简化版的SMO算法比较耗时. 完整版的SMO通过一个外循环来选择第一个 \(\alpha\), 通过一个内循环来选择第二个 \(\alpha\).
选择第一个 \(\alpha\) 时, 使用两种方法交替进行: 在所有数据集上进行单遍扫描; 在非边界 \(\alpha\) 中实现单遍扫描. 非边界, 指的是 \(\alpha\) 的值不等于0或C.
Generated by Emacs 25.x(Org mode 8.x)
Copyright © 2014 - Pinvon - Powered by EGO
