Fabric交易流程
Table of Contents
交易流程
A: 买萝卜
B: 卖萝卜
A和B分别有一个Peer, 通过区块链网络, A和B进行交易(Transactions), 并与账本(Ledger)进行交互.
假设
- 已经建立Channel.
- 应用程序的用户已注册.
- 应用程序的用户完成了CA注册, 有需要的加密材料, 可以在网络上进行身份验证.
- Chaincode已安装在Peer上, 已在Channel上实例化.
- Chaincode包含一组交易指令和商定萝卜价格的业务逻辑.
- 背书策略(Endorsement Policy)已经为Chaincode设置完成, 并规定, 任何一笔交易, 需要由PeerA和PeerB共同背书.
A发起交易
A发起购买萝卜的请求给PeerA和PeerB. (因为在假设中, 背书策略规定任何一笔交易需要由PeerA和PeerB共同背书).
应用程序利用SDK的API生成交易提议(Transaction Proposal). 交易提议请求调用Chaincode的函数, 因此, 数据可以被读取或写入账本.
SDK根据A的加密凭证, 为此交易生成唯一签名.
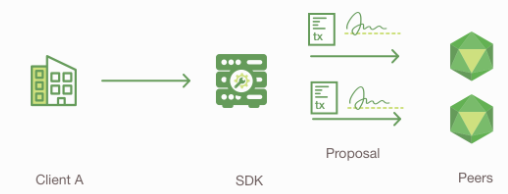
背书节点(Endorsing Peers)校验签名并执行交易
背书节点的工作如下:
- 交易提议的格式是否正确
- 交易提议在以前是否被提交过
- 签名是否有效
- 提交者A是否在该Channel上被授权执行提议操作(要确保提供者满足Channel的写入策略)
背书节点将交易提议作为Chaincode的函数的输入参数.
Chaincode在状态数据库(State Database)上执行, 生成交易结果(响应值, 读取集合, 写入集合). 此时还不更新账本
背书节点将交易提议响应(包括交易结果和背书节点的签名)发给SDK, SDK解析这些数据给应用程序使用.
MSP是一个节点组件(Peer Component), 校验来自客户端的交易请求, 并为交易结果签名(背书).
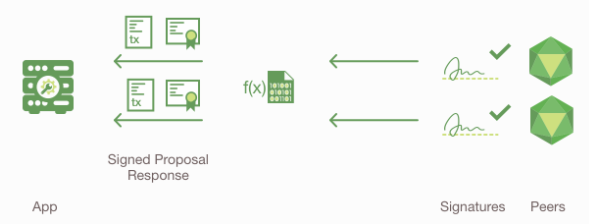
检查交易提交响应
应用程序验证所有背书节点(Endorsing Peer)的签名, 并比较所有的交易提交响应是否相同(因为背书节点有PeerA和PeerB, 它们分别会回复一个交易提交响应).
如果本次交易调用的只是Chaincode的查询账本的函数, 则应用程序会检查查询响应, 并且通常不会将此交易提交给排序服务(Ordering Service).
如果本次交易调用的是Chaincode的更新账本的函数, 则应用程序在提交之前, 会先确定PeerA和PeerB是否都已经背书.
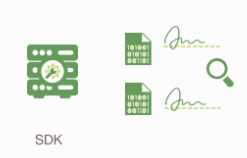
客户端将所有背书组装进交易
应用程序将交易提议和交易提议响应组成的交易消息广播给排序服务(Ordering Service). 交易消息包括以下内容:
- 读写集合
- 所有背书节点的签名和频道ID
排序服务将每个Channel上的交易按时间顺序排序, 创建各个Channel的交易区块.
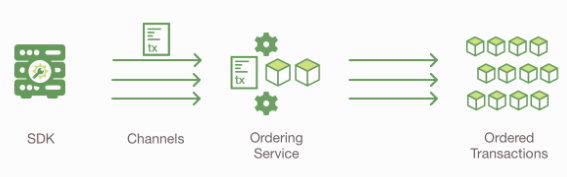
交易被确认并提交
交易区块被交付给Channel中的所有节点. 这些节点所做的事情如下:
- 对区块中的交易进行确认, 确保背书策略得到满足
- 确保账本状态中读取的变量集合在交易执行后没有变化过
- 标记交易区块是否有效
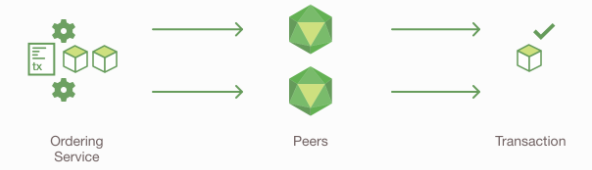
账本更新
所有Peer会将所区块追加到Channel的链中, 并且对于每一笔有效的交易, 写集合都会被提交给当前的状态数据库.
通知客户端, 此交易已追加到链中.
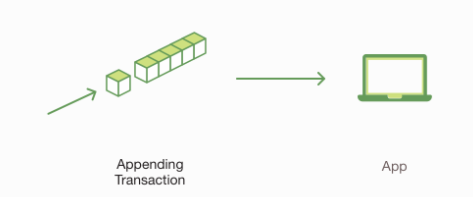
通俗交易流程
Chaincode规定背书策略, 如交易生效的前提是PeerA, PeerB, PeerC中有两个以上的节点批准了这笔交易.
Client买车, 生成交易请求, 触发Chaincode, 将该交易请求发给PeerA, PeerB, PeerC.
如果交易可信, PeerA, PeerB, PeerC根据交易请求进行运算, 生成交易结果, 反馈给Client. (这时还不写入区块链)
Client对交易结果进行确认, 如果三个背书节点返回的交易结果一致, 则把交易发给排序模块.
排序模块将所有收到的交易根据时间排序, 打包成区块, 发给所有节点.
所有节点检查每笔交易是否满足背书策略.
如果交易成功, 节点通知用户, 交易已加入区块链.
IBM视频
事务: 与账本的一次交互.
账本
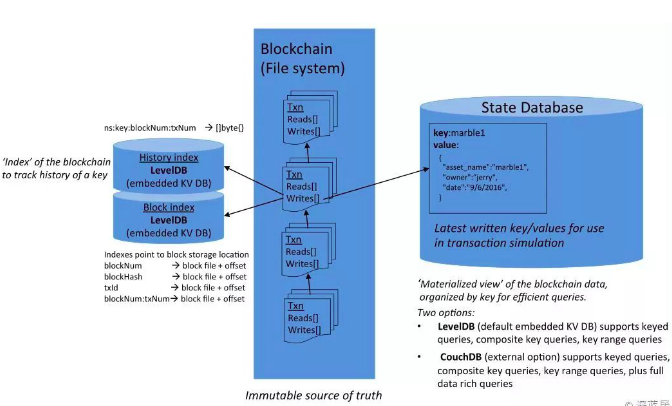
在Fabric 1.0中, 账本分成了3种:
- Blockchain: 存放在committer节点上, 存储了事务的读写集.
- LevelDB: 对事务进行索引, 方便检索区块链.
- State Database: 存储chaincode操作的实际数据, 是一个k-v数据对.
事务提交过程
使用example中A给B转账10元的例子.
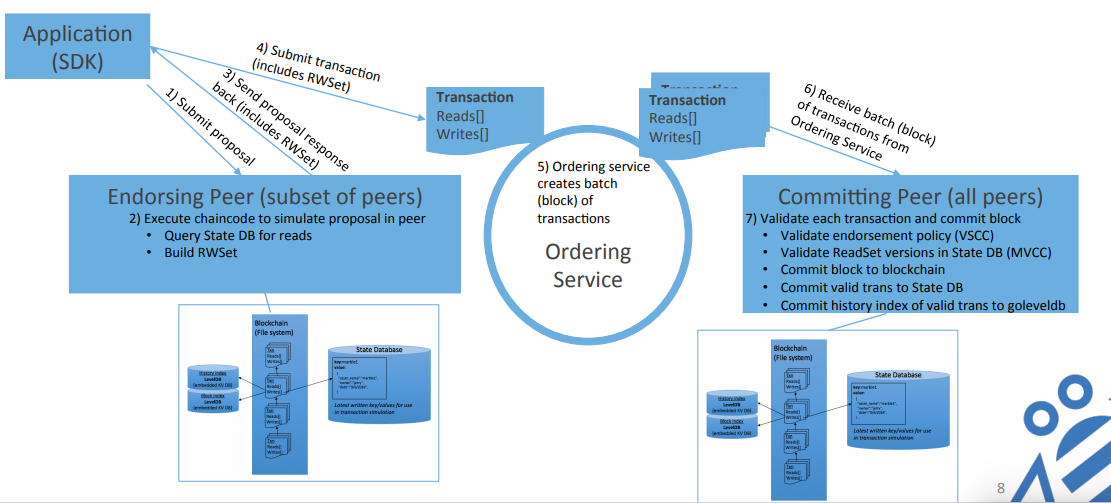
- SDK构造参数 {"Args":["invoke","a","b","10"]}, 发送到背书节点.
- 背书节点与chaincode通信, 为chaincode提供模拟的State Database的读写集. 即模拟交易完成, 但不会真的写入账本.
- 背书节点把读写集连同签名返回SDK.
- SDK再把读写集发给Orderer节点, Orderer节点进行共识排序, 测试阶段使用solo策略, 即只启动一个Orderer节点, 没有容错. 但在生产环境中, 要使用kafka.
- Orderer只负责排序和打包工作, 产生一个区块. 可以产生区块的情况有两个, 一个是事务很多, 区块达到了设定的大小; 另一个是事务很少, Orderer节点等到超时了. 这些在configtx.yaml中可以设置.
- Orderer节点将区块发给committer节点.
- committer节点对区块里的数据进行检验, 检验其是否正确. 然后验证每个事务, 主要是验证事务中的读写集与state database中的是否一致. 验证通过后写入区块链.
关于背书与验证的例子. 在背书的时候, a给b转账10元, 然后b给a转账10元, 背书节点都会告诉SDK成功. 但是Fabric不支持对同一个数据的并发事务处理, 所以在验证阶段, b给a转账10元会验证失败.
关于共识
在fabric中, 共识过程意味着多个节点对于某一批交易的发生顺序, 合法性, 它们对账本状态的更新结构达成一致的观点. fabric中的共识包括背书, 排序和验证三个环节的保障.
交易必须按照发生的顺序写入账本. 为了实现这一点, 必须建立交易的顺序, 并且能拒绝错误.
不过, 共识并不仅仅是同意交易顺序, 而是在整个交易流程中的基本作用, 从提案, 背书, 排序到验证, 在hyperledger fabric中强调了这种差异化. 即: 共识被定义为对区块的一组交易的正确性的全面验证.
目前的hyperledger fabric中的共识机制, 目前有solo, kafka.
solo由一个为所有客户服务的单一节点组成, 所以不需要"共识", 因为有一个中央权威机构. 适用于测试阶段. 其过程如下: peer通过grpc协议发起通信, 与orderer连接成功之后, 向orderer发送消息. orderer将接收到的消息生成数据块, 存入账本.
在生产环境部署, 需要使用kafka的排序功能实现共识.
Generated by Emacs 25.x(Org mode 8.x)
Copyright © 2014 - pinvon - Powered by EGO
